 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking Face Generation
Talking face generation is the process of generating videos of a person speaking based on an audio recording of their voice.
Papers and Code
LPIPS-AttnWav2Lip: Generic Audio-Driven lip synchronization for Talking Head Generation in the Wild
Jan 30, 2026Researchers have shown a growing interest in Audio-driven Talking Head Generation. The primary challenge in talking head generation is achieving audio-visual coherence between the lips and the audio, known as lip synchronization. This paper proposes a generic method, LPIPS-AttnWav2Lip, for reconstructing face images of any speaker based on audio. We used the U-Net architecture based on residual CBAM to better encode and fuse audio and visual modal information. Additionally, the semantic alignment module extends the receptive field of the generator network to obtain the spatial and channel information of the visual features efficiently; and match statistical information of visual features with audio latent vector to achieve the adjustment and injection of the audio content information to the visual information. To achieve exact lip synchronization and to generate realistic high-quality images, our approach adopts LPIPS Loss, which simulates human judgment of image quality and reduces instability possibility during the training process. The proposed method achieves outstanding performance in terms of lip synchronization accuracy and visual quality as demonstrated by subjective and objective evaluation results. The code for the paper is available at the following link: https://github.com/FelixChan9527/LPIPS-AttnWav2Lip
* This paper has been accepted by Elsevier's \textit{Speech Communication} journal. Official publication link: https://doi.org/10.1016/j.specom.2023.103028 The code for the paper is available at the following link: https://github.com/FelixChan9527/LPIPS-AttnWav2Lip
MIRRORTALK: Forging Personalized Avatars Via Disentangled Style and Hierarchical Motion Control
Jan 30, 2026Synthesizing personalized talking faces that uphold and highlight a speaker's unique style while maintaining lip-sync accuracy remains a significant challenge. A primary limitation of existing approaches is the intrinsic confounding of speaker-specific talking style and semantic content within facial motions, which prevents the faithful transfer of a speaker's unique persona to arbitrary speech. In this paper, we propose MirrorTalk, a generative framework based on a conditional diffusion model, combined with a Semantically-Disentangled Style Encoder (SDSE) that can distill pure style representations from a brief reference video. To effectively utilize this representation, we further introduce a hierarchical modulation strategy within the diffusion process. This mechanism guides the synthesis by dynamically balancing the contributions of audio and style features across distinct facial regions, ensuring both precise lip-sync accuracy and expressive full-face dynamics. Extensive experiments demonstrate that MirrorTalk achieves significant improvements over state-of-the-art methods in terms of lip-sync accuracy and personalization preservation.
Generalizable and Animatable 3D Full-Head Gaussian Avatar from a Single Image
Jan 19, 2026Building 3D animatable head avatars from a single image is an important yet challenging problem. Existing methods generally collapse under large camera pose variations, compromising the realism of 3D avatars. In this work, we propose a new framework to tackle the novel setting of one-shot 3D full-head animatable avatar reconstruction in a single feed-forward pass, enabling real-time animation and simultaneous 360$^\circ$ rendering views. To facilitate efficient animation control, we model 3D head avatars with Gaussian primitives embedded on the surface of a parametric face model within the UV space. To obtain knowledge of full-head geometry and textures, we leverage rich 3D full-head priors within a pretrained 3D generative adversarial network (GAN) for global full-head feature extraction and multi-view supervision. To increase the fidelity of the 3D reconstruction of the input image, we take advantage of the symmetric nature of the UV space and human faces to fuse local fine-grained input image features with the global full-head textures. Extensive experiments demonstrate the effectiveness of our method, achieving high-quality 3D full-head modeling as well as real-time animation, thereby improving the realism of 3D talking avatars.
RSATalker: Realistic Socially-Aware Talking Head Generation for Multi-Turn Conversation
Jan 15, 2026Talking head generation is increasingly important in virtual reality (VR), especially for social scenarios involving multi-turn conversation. Existing approaches face notable limitations: mesh-based 3D methods can model dual-person dialogue but lack realistic textures, while large-model-based 2D methods produce natural appearances but incur prohibitive computational costs. Recently, 3D Gaussian Splatting (3DGS) based methods achieve efficient and realistic rendering but remain speaker-only and ignore social relationships. We introduce RSATalker, the first framework that leverages 3DGS for realistic and socially-aware talking head generation with support for multi-turn conversation. Our method first drives mesh-based 3D facial motion from speech, then binds 3D Gaussians to mesh facets to render high-fidelity 2D avatar videos. To capture interpersonal dynamics, we propose a socially-aware module that encodes social relationships, including blood and non-blood as well as equal and unequal, into high-level embeddings through a learnable query mechanism. We design a three-stage training paradigm and construct the RSATalker dataset with speech-mesh-image triplets annotated with social relationships. Extensive experiments demonstrate that RSATalker achieves state-of-the-art performance in both realism and social awareness. The code and dataset will be released.
Now You See Me, Now You Don't: A Unified Framework for Expression Consistent Anonymization in Talking Head Videos
Jan 14, 2026Face video anonymization is aimed at privacy preservation while allowing for the analysis of videos in a number of computer vision downstream tasks such as expression recognition, people tracking, and action recognition. We propose here a novel unified framework referred to as Anon-NET, streamlined to de-identify facial videos, while preserving age, gender, race, pose, and expression of the original video. Specifically, we inpaint faces by a diffusion-based generative model guided by high-level attribute recognition and motion-aware expression transfer. We then animate deidentified faces by video-driven animation, which accepts the de-identified face and the original video as input. Extensive experiments on the datasets VoxCeleb2, CelebV-HQ, and HDTF, which include diverse facial dynamics, demonstrate the effectiveness of AnonNET in obfuscating identity while retaining visual realism and temporal consistency. The code of AnonNet will be publicly released.
Efficient and Robust Video Defense Framework against 3D-field Personalized Talking Face
Dec 24, 2025State-of-the-art 3D-field video-referenced Talking Face Generation (TFG) methods synthesize high-fidelity personalized talking-face videos in real time by modeling 3D geometry and appearance from reference portrait video. This capability raises significant privacy concerns regarding malicious misuse of personal portraits. However, no efficient defense framework exists to protect such videos against 3D-field TFG methods. While image-based defenses could apply per-frame 2D perturbations, they incur prohibitive computational costs, severe video quality degradation, failing to disrupt 3D information for video protection. To address this, we propose a novel and efficient video defense framework against 3D-field TFG methods, which protects portrait video by perturbing the 3D information acquisition process while maintain high-fidelity video quality. Specifically, our method introduces: (1) a similarity-guided parameter sharing mechanism for computational efficiency, and (2) a multi-scale dual-domain attention module to jointly optimize spatial-frequency perturbations. Extensive experiments demonstrate that our proposed framework exhibits strong defense capability and achieves a 47x acceleration over the fastest baseline while maintaining high fidelity. Moreover, it remains robust against scaling operations and state-of-the-art purification attacks, and the effectiveness of our design choices is further validated through ablation studies. Our project is available at https://github.com/Richen7418/VDF.
FacEDiT: Unified Talking Face Editing and Generation via Facial Motion Infilling
Dec 16, 2025
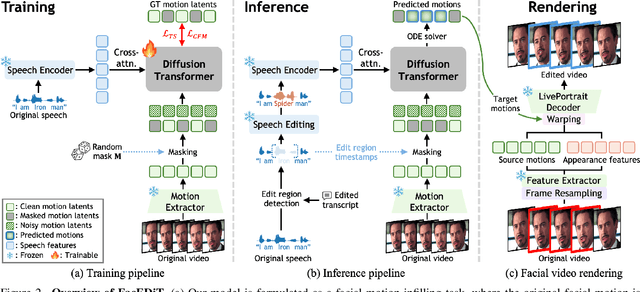


Talking face editing and face generation have often been studied as distinct problems. In this work, we propose viewing both not as separate tasks but as subtasks of a unifying formulation, speech-conditional facial motion infilling. We explore facial motion infilling as a self-supervised pretext task that also serves as a unifying formulation of dynamic talking face synthesis. To instantiate this idea, we propose FacEDiT, a speech-conditional Diffusion Transformer trained with flow matching. Inspired by masked autoencoders, FacEDiT learns to synthesize masked facial motions conditioned on surrounding motions and speech. This formulation enables both localized generation and edits, such as substitution, insertion, and deletion, while ensuring seamless transitions with unedited regions. In addition, biased attention and temporal smoothness constraints enhance boundary continuity and lip synchronization. To address the lack of a standard editing benchmark, we introduce FacEDiTBench, the first dataset for talking face editing, featuring diverse edit types and lengths, along with new evaluation metrics. Extensive experiments validate that talking face editing and generation emerge as subtasks of speech-conditional motion infilling; FacEDiT produces accurate, speech-aligned facial edits with strong identity preservation and smooth visual continuity while generalizing effectively to talking face generation.
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Dec 22, 2025Despite significant advances in talking avatar generation, existing methods face critical challenges: insufficient text-following capability for diverse actions, lack of temporal alignment between actions and audio content, and dependency on additional control signals such as pose skeletons. We present ActAvatar, a framework that achieves phase-level precision in action control through textual guidance by capturing both action semantics and temporal context. Our approach introduces three core innovations: (1) Phase-Aware Cross-Attention (PACA), which decomposes prompts into a global base block and temporally-anchored phase blocks, enabling the model to concentrate on phase-relevant tokens for precise temporal-semantic alignment; (2) Progressive Audio-Visual Alignment, which aligns modality influence with the hierarchical feature learning process-early layers prioritize text for establishing action structure while deeper layers emphasize audio for refining lip movements, preventing modality interference; (3) A two-stage training strategy that first establishes robust audio-visual correspondence on diverse data, then injects action control through fine-tuning on structured annotations, maintaining both audio-visual alignment and the model's text-following capabilities. Extensive experiments demonstrate that ActAvatar significantly outperforms state-of-the-art methods in both action control and visual quality.
TAVID: Text-Driven Audio-Visual Interactive Dialogue Generation
Dec 23, 2025The objective of this paper is to jointly synthesize interactive videos and conversational speech from text and reference images. With the ultimate goal of building human-like conversational systems, recent studies have explored talking or listening head generation as well as conversational speech generation. However, these works are typically studied in isolation, overlooking the multimodal nature of human conversation, which involves tightly coupled audio-visual interactions. In this paper, we introduce TAVID, a unified framework that generates both interactive faces and conversational speech in a synchronized manner. TAVID integrates face and speech generation pipelines through two cross-modal mappers (i.e., a motion mapper and a speaker mapper), which enable bidirectional exchange of complementary information between the audio and visual modalities. We evaluate our system across four dimensions: talking face realism, listening head responsiveness, dyadic interaction fluency, and speech quality. Extensive experiments demonstrate the effectiveness of our approach across all these aspects.
VASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image
Dec 16, 2025We propose VASA-3D, an audio-driven, single-shot 3D head avatar generator. This research tackles two major challenges: capturing the subtle expression details present in real human faces, and reconstructing an intricate 3D head avatar from a single portrait image. To accurately model expression details, VASA-3D leverages the motion latent of VASA-1, a method that yields exceptional realism and vividness in 2D talking heads. A critical element of our work is translating this motion latent to 3D, which is accomplished by devising a 3D head model that is conditioned on the motion latent. Customization of this model to a single image is achieved through an optimization framework that employs numerous video frames of the reference head synthesized from the input image. The optimization takes various training losses robust to artifacts and limited pose coverage in the generated training data. Our experiment shows that VASA-3D produces realistic 3D talking heads that cannot be achieved by prior art, and it supports the online generation of 512x512 free-viewpoint videos at up to 75 FPS, facilitating more immersive engagements with lifelike 3D avatars.